
{kind=link}

SolidityBench โดย IQ ได้เปิดตัวเป็นลีดเดอร์บอร์ดแรกที่ประเมิน LLM ในการสร้างโค้ด Solidity มีจำหน่ายที่ กอดหน้าโดยเปิดตัวเกณฑ์มาตรฐานที่เป็นนวัตกรรมใหม่ 2 รายการ ได้แก่ NaïveJudge และ HumanEval for Solidity ซึ่งออกแบบมาเพื่อประเมินและจัดอันดับความสามารถของโมเดล AI ในการสร้างโค้ดสัญญาอัจฉริยะ
พัฒนาโดยไอคิว BrainDAO SolidityBench ซึ่งเป็นส่วนหนึ่งของชุด IQ Code ที่กำลังจะมีขึ้น ทำหน้าที่ปรับแต่ง EVMind LLM ของตนเอง และเปรียบเทียบกับโมเดลทั่วไปและโมเดลที่สร้างโดยชุมชน IQ Code มุ่งหวังที่จะนำเสนอโมเดล AI ที่ปรับแต่งสำหรับการสร้างและตรวจสอบโค้ดสัญญาอัจฉริยะ โดยตอบสนองความต้องการที่เพิ่มขึ้นสำหรับแอปพลิเคชันบล็อกเชนที่ปลอดภัยและมีประสิทธิภาพ
อย่างที่ไอคิวบอก CryptoSlateNaïveJudge นำเสนอแนวทางใหม่โดยมอบหมายให้ LLM ดำเนินการสัญญาอัจฉริยะตามข้อกำหนดรายละเอียดที่ได้รับจากสัญญา OpenZeppelin ที่ตรวจสอบแล้ว สัญญาเหล่านี้ถือเป็นมาตรฐานทองคำในด้านความถูกต้องและมีประสิทธิภาพ โค้ดที่สร้างขึ้นจะได้รับการประเมินเทียบกับการใช้งานอ้างอิงโดยใช้เกณฑ์ต่างๆ เช่น ความสมบูรณ์ของฟังก์ชัน การยึดมั่นในแนวทางปฏิบัติที่ดีที่สุดและมาตรฐานความปลอดภัยของ Solidity และประสิทธิภาพการปรับให้เหมาะสม
กระบวนการประเมินใช้ประโยชน์ LLM ขั้นสูงรวมถึง GPT-4 และ Claude 3.5 Sonnet ของ OpenAI เวอร์ชันต่างๆ ในฐานะผู้ตรวจสอบโค้ดที่เป็นกลาง พวกเขาประเมินโค้ดตามเกณฑ์ที่เข้มงวด รวมถึงการใช้งานฟังก์ชันหลักทั้งหมด การจัดการ Edge case การจัดการข้อผิดพลาด การใช้ไวยากรณ์ที่เหมาะสม และโครงสร้างโค้ดโดยรวมและการบำรุงรักษา
ข้อควรพิจารณาในการเพิ่มประสิทธิภาพ เช่น ประสิทธิภาพการใช้ก๊าซและการจัดการการจัดเก็บก็ได้รับการประเมินเช่นกัน คะแนนมีตั้งแต่ 0 ถึง 100 ซึ่งเป็นการประเมินที่ครอบคลุมทั้งในด้านฟังก์ชันการทำงาน ความปลอดภัย และประสิทธิภาพ ซึ่งสะท้อนให้เห็นถึงความซับซ้อนของการพัฒนาสัญญาอัจฉริยะระดับมืออาชีพ
โมเดล AI ใดดีที่สุดสำหรับการพัฒนาสัญญาอัจฉริยะที่แข็งแกร่ง
ผลการเปรียบเทียบแสดงให้เห็นว่าโมเดล GPT-4o ของ OpenAI ได้รับคะแนนรวมสูงสุดที่ 80.05 โดยมีคะแนน NaïveJudge อยู่ที่ 72.18 และอัตราการส่งผ่าน HumanEval for Solidity อยู่ที่ 80% ที่ go@1 และ 92% ที่ go@3
สิ่งที่น่าสนใจก็คือ โมเดลการให้เหตุผลใหม่ๆ เช่น o1-พรีวิวของ OpenAI และ o1-mini ขึ้นจ่าฝูงด้วยคะแนน 77.61 และ 75.08 ตามลำดับ แบบจำลองจาก Anthropic และ XAI รวมถึง Claude 3.5 Sonnet และ grok-2 แสดงให้เห็นถึงประสิทธิภาพการแข่งขันด้วยคะแนนรวมอยู่ที่ประมาณ 74 Llama-3.1-Nemotron-70B ของ Nvidia ทำคะแนนต่ำสุดใน 10 อันดับแรกที่ 52.54
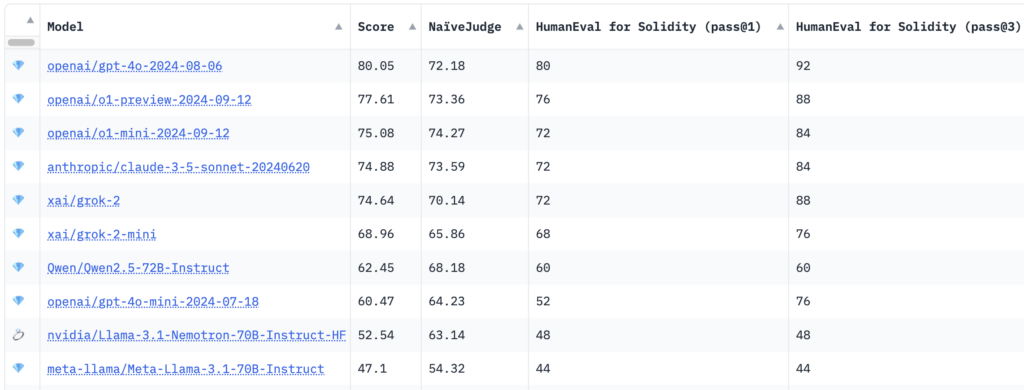
ตาม IQ นั้น HumanEval for Solidity จะปรับเกณฑ์มาตรฐาน HumanEval ดั้งเดิมของ OpenAI จาก Python เป็น Solidity ซึ่งครอบคลุม 25 ภารกิจที่มีความยากต่างกันไป แต่ละงานประกอบด้วยการทดสอบที่สอดคล้องกันซึ่งเข้ากันได้กับ Hardhat ซึ่งเป็นสภาพแวดล้อมการพัฒนา Ethereum ที่ได้รับความนิยม ซึ่งอำนวยความสะดวกในการรวบรวมและทดสอบโค้ดที่สร้างขึ้นอย่างแม่นยำ ตัวชี้วัดการประเมิน go@1 และ go@3 วัดความสำเร็จของแบบจำลองทั้งจากการพยายามครั้งแรกและการพยายามหลายครั้ง โดยให้ข้อมูลเชิงลึกเกี่ยวกับความแม่นยำและความสามารถในการแก้ปัญหา
เป้าหมายของการใช้โมเดล AI ในการพัฒนาสัญญาอัจฉริยะ
ด้วยการแนะนำเกณฑ์มาตรฐานเหล่านี้ SolidityBench พยายามที่จะพัฒนาสัญญาอัจฉริยะที่ได้รับความช่วยเหลือจาก AI โดยสนับสนุนการสร้างแบบจำลอง AI ที่ซับซ้อนและเชื่อถือได้มากขึ้น ขณะเดียวกันก็ช่วยให้นักพัฒนาและนักวิจัยได้รับข้อมูลเชิงลึกอันมีค่าเกี่ยวกับความสามารถและข้อจำกัดในปัจจุบันของ AI ในการพัฒนา Solidity
ชุดเครื่องมือเปรียบเทียบมีเป้าหมายเพื่อพัฒนา EVMind LLM ของ IQ Code และยังกำหนดมาตรฐานใหม่สำหรับการพัฒนาสัญญาอัจฉริยะที่ได้รับความช่วยเหลือจาก AI ทั่วทั้งระบบนิเวศบล็อกเชน ความคิดริเริ่มนี้หวังว่าจะตอบสนองความต้องการที่สำคัญในอุตสาหกรรมซึ่งมีความต้องการ ปลอดภัย และสัญญาอัจฉริยะที่มีประสิทธิภาพยังคงเติบโตอย่างต่อเนื่อง
นักพัฒนา นักวิจัย และผู้ที่ชื่นชอบ AI ได้รับเชิญให้สำรวจและมีส่วนร่วมใน SolidityBench ซึ่งมีเป้าหมายเพื่อขับเคลื่อนการปรับปรุงโมเดล AI อย่างต่อเนื่อง ส่งเสริมแนวทางปฏิบัติที่ดีที่สุด และพัฒนาแอปพลิเคชันที่มีการกระจายอำนาจ
เยี่ยมชม SolidityBench ลีดเดอร์บอร์ด บน Hugging Face เพื่อเรียนรู้เพิ่มเติมและเริ่มเปรียบเทียบโมเดลการสร้าง Solidity