

{kind=link}
T'was the day earlier than genesis, when all was ready, geth was in sync, my beacon node paired. Firewalls configured, VLANs galore, hours of preparation meant nothing ignored.
Then unexpectedly the whole lot went awry, the SSD in my system determined to die. My configs had been gone, chain knowledge was historical past, nothing to do however belief in subsequent day supply.
I discovered myself designing backups and redundancies. Difficult methods consumed my fantasies. Considering additional I got here to grasp: worrying about these sorts of failures was fairly unwise.
กิจกรรม
สายสัญญาณบีคอนมีกลไกหลายประการเพื่อกระตุ้นพฤติกรรมของเครื่องมือตรวจสอบความถูกต้อง ซึ่งทั้งหมดนี้ขึ้นอยู่กับสถานะปัจจุบันของเครือข่าย ดังนั้นจึงเป็นเรื่องสำคัญที่จะต้องพิจารณากรณีความล้มเหลวเหล่านี้ในบริบทที่กว้างกว่าว่าเครื่องมือตรวจสอบความถูกต้องอื่นๆ อาจล้มเหลวอย่างไรเมื่อตัดสินใจว่าอะไรคืออะไร และอะไร ไม่ใช่วิธีที่คุ้มค่าในการรักษาความปลอดภัยโหนดของคุณ
ในฐานะผู้ตรวจสอบที่ใช้งานอยู่ ยอดคงเหลือของคุณจะเพิ่มขึ้นหรือลดลง โดยจะไม่คลาดเคลื่อน* ดังนั้นวิธีที่สมเหตุสมผลในการเพิ่มผลกำไรสูงสุดของคุณก็คือการลดข้อเสียของคุณให้เหลือน้อยที่สุด มี 3 วิธีในการลดยอดเงินคงเหลือของคุณด้วยห่วงโซ่บีคอน:
- บทลงโทษ จะออกให้เมื่อเครื่องมือตรวจสอบความถูกต้องของคุณพลาดหน้าที่อย่างใดอย่างหนึ่ง (เช่น เนื่องจากออฟไลน์อยู่)
- การรั่วไหลของการไม่ใช้งาน ถูกแจกจ่ายให้กับผู้ตรวจสอบที่พลาดหน้าที่ในขณะที่เครือข่ายไม่สามารถสรุปผลได้ (เช่น เมื่อเครื่องมือตรวจสอบความถูกต้องของคุณออฟไลน์มีความสัมพันธ์อย่างมากกับเครื่องมือตรวจสอบอื่น ๆ ที่กำลังออฟไลน์)
- เฉือน จะมอบให้กับผู้ตรวจสอบความถูกต้องที่สร้างบล็อกหรือการรับรองที่ขัดแย้งกันและสามารถนำไปใช้ในการโจมตีได้
* โดยเฉลี่ยแล้ว ยอดคงเหลือของผู้ตรวจสอบความถูกต้องอาจเท่าเดิม แต่สำหรับหน้าที่ใดๆ ก็ตาม พวกเขาจะได้รับรางวัลหรือถูกลงโทษ
ความสัมพันธ์
ผลกระทบของเครื่องมือตรวจสอบความถูกต้องเพียงตัวเดียวในขณะออฟไลน์หรือมีพฤติกรรมแบบเฉือนนั้นมีผลเพียงเล็กน้อยในแง่ของความสมบูรณ์โดยรวมของสายสัญญาณบีคอน จึงไม่ถูกลงโทษหนัก ในทางตรงกันข้าม หากเครื่องมือตรวจสอบความถูกต้องจำนวนมากออฟไลน์ ยอดคงเหลือของเครื่องมือตรวจสอบความถูกต้องแบบออฟไลน์จะลดลงอย่างรวดเร็วยิ่งขึ้น
ในทำนองเดียวกัน หากผู้ตรวจสอบความถูกต้องจำนวนมากดำเนินการแบบเฉือนได้ในเวลาเดียวกัน จากมุมมองของบีคอนเชน สิ่งนี้จะแยกไม่ออกจากการโจมตี ดังนั้นจึงได้รับการปฏิบัติเช่นนี้ และเงินเดิมพันของผู้ตรวจสอบที่กระทำผิด 100% จะถูกเผา
เนื่องจากสิ่งจูงใจ “การต่อต้านความสัมพันธ์” เหล่านี้ ผู้ตรวจสอบความถูกต้องจึงควรกังวล มากกว่า เกี่ยวกับความล้มเหลวที่อาจส่งผลกระทบต่อผู้อื่นในเวลาเดียวกัน แทนที่จะแยกประเด็นของแต่ละบุคคล
สาเหตุและความน่าจะเป็น
ลองคิดถึงกรณีความล้มเหลวบางกรณี และตรวจสอบผ่านเลนส์ว่าจะมีกรณีอื่นๆ อีกกี่กรณีที่ได้รับผลกระทบในเวลาเดียวกัน และผู้ตรวจสอบของคุณจะถูกลงโทษอย่างรุนแรงเพียงใด

ฉันไม่เห็นด้วยกับ @econoar ที่นี่ ว่าสิ่งเหล่านี้เป็น กรณีที่เลวร้ายที่สุด ปัญหา. สิ่งเหล่านี้เป็นปัญหาระดับปานกลางมากกว่า ความล้มเหลวของที่อยู่ UPS ที่บ้านและ WAN แบบคู่ไม่มีความสัมพันธ์กับผู้ใช้รายอื่น ดังนั้นคุณจึงไม่ควรกังวลมากนัก
🌍 อินเทอร์เน็ต/ไฟฟ้าขัดข้อง
หากคุณตรวจสอบความถูกต้องจากที่บ้าน มีความเป็นไปได้สูงที่คุณจะพบกับความล้มเหลวอย่างใดอย่างหนึ่งเหล่านี้ในอนาคต อินเทอร์เน็ตที่อยู่อาศัยและการเชื่อมต่อไฟฟ้าไม่รับประกันเวลาทำงาน อย่างไรก็ตาม เมื่ออินเทอร์เน็ตขัดข้องหรือไฟฟ้าดับ โดยปกติไฟฟ้าดับจะจำกัดอยู่เฉพาะในพื้นที่ของคุณ และแม้กระทั่งเพียงไม่กี่ชั่วโมงเท่านั้น
เว้นแต่คุณจะมี มาก อินเทอร์เน็ต/พลังงานขาดหาย อาจไม่คุ้มค่าที่จะจ่ายสำหรับการเชื่อมต่อที่ล่ม คุณจะได้รับการลงโทษสองสามชั่วโมง แต่เมื่อเครือข่ายที่เหลือทำงานตามปกติ บทลงโทษของคุณจะเท่ากับคร่าวๆ ของรางวัลที่คุณจะได้รับในช่วงเวลาเดียวกัน กล่าวอีกนัยหนึ่งก เค ความล้มเหลวที่ใช้เวลานานหนึ่งชั่วโมงจะทำให้ยอดคงเหลือของเครื่องมือตรวจสอบความถูกต้องของคุณกลับมาที่ระดับเดิมโดยประมาณ เค ชั่วโมงก่อนเกิดความล้มเหลว และใน เค ชั่วโมงเพิ่มเติม ยอดคงเหลือของเครื่องมือตรวจสอบความถูกต้องของคุณจะกลับมาเป็นจำนวนก่อนเกิดความล้มเหลว
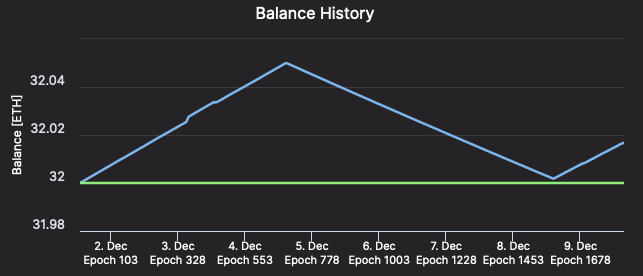
–เครื่องมือตรวจสอบ #12661 ได้รับ ETH กลับคืนมาอย่างรวดเร็วเหมือนกับที่สูญเสียไป – บีคอนชา.อิน
🛠 ฮาร์ดแวร์ล้มเหลว
เช่นเดียวกับความล้มเหลวของอินเทอร์เน็ต ความล้มเหลวของฮาร์ดแวร์จะเกิดขึ้นแบบสุ่ม และเมื่อเป็นเช่นนั้น โหนดของคุณอาจล่มเป็นเวลาสองสามวัน การพิจารณาผลตอบแทนที่คาดหวังตลอดอายุการใช้งานของเครื่องมือตรวจสอบความถูกต้องเทียบกับต้นทุนของฮาร์ดแวร์ที่ซ้ำซ้อนถือว่ามีคุณค่า ค่าที่คาดหวังของความล้มเหลว (บทลงโทษออฟไลน์คูณโอกาสที่จะเกิดขึ้น) มากกว่าต้นทุนของฮาร์ดแวร์สำรองหรือไม่
โดยส่วนตัวแล้ว โอกาสที่จะเกิดความล้มเหลวนั้นต่ำเพียงพอและต้นทุนของฮาร์ดแวร์ที่ซ้ำซ้อนทั้งหมดก็สูงเพียงพอจนเกือบจะไม่คุ้มค่าอย่างแน่นอน แต่ขอย้ำอีกครั้งว่าฉันไม่ใช่วาฬ 🐳 ; เช่นเดียวกับสถานการณ์ความล้มเหลวใดๆ คุณจำเป็นต้องประเมินว่าสิ่งนี้จะนำไปใช้กับสถานการณ์เฉพาะของคุณได้อย่างไร
☁️บริการคลาวด์ล้มเหลว
บางที เพื่อหลีกเลี่ยงความเสี่ยงของฮาร์ดแวร์หรืออินเทอร์เน็ตล้มเหลวโดยสิ้นเชิง คุณจึงตัดสินใจเลือกผู้ให้บริการระบบคลาวด์ ด้วยผู้ให้บริการคลาวด์ คุณได้นำความเสี่ยงของความล้มเหลวที่สัมพันธ์กัน คำถามที่สำคัญคือ มีผู้ตรวจสอบความถูกต้องรายอื่นกี่รายที่ใช้ผู้ให้บริการคลาวด์รายเดียวกับคุณ
หนึ่งสัปดาห์ก่อนกำเนิด Amazon AWS เกิดการหยุดทำงานเป็นเวลานาน ซึ่งส่งผลกระทบต่อเว็บส่วนใหญ่ หากมีสิ่งที่คล้ายกันเกิดขึ้นตอนนี้ ผู้ตรวจสอบความถูกต้องเพียงพอจะออฟไลน์ในเวลาเดียวกันกับที่บทลงโทษการไม่ใช้งานจะเกิดขึ้น
ที่แย่กว่านั้นคือ หากผู้ให้บริการคลาวด์ทำซ้ำ VM ที่รันโหนดของคุณ และปล่อยให้โหนดเก่าและโหนดใหม่ทำงานพร้อมกันโดยไม่ตั้งใจ คุณอาจถูกเฉือนได้ (บทลงโทษที่เกิดขึ้นจะเลวร้ายอย่างยิ่งหากการทำซ้ำโดยไม่ตั้งใจนี้ส่งผลกระทบต่อโหนดอื่นๆ จำนวนมาก ด้วย).
หากคุณยืนกรานที่จะพึ่งพาผู้ให้บริการคลาวด์ ให้พิจารณาเปลี่ยนไปใช้ผู้ให้บริการรายเล็ก มันอาจช่วยให้คุณประหยัด ETH ได้มาก
🥩 บริการปักหลัก
มี บริการปักหลักหลายแห่ง บน mainnet ในปัจจุบันด้วยระดับการกระจายอำนาจที่แตกต่างกัน แต่ทั้งหมดมีความเสี่ยงที่เพิ่มขึ้นของความล้มเหลวที่สัมพันธ์กัน หากคุณเชื่อถือ ETH ของคุณ บริการเหล่านี้เป็นองค์ประกอบที่จำเป็นของระบบนิเวศ eth2 โดยเฉพาะอย่างยิ่งสำหรับผู้ที่มีจำนวน ETH น้อยกว่า 32 หรือไม่มีความรู้ด้านเทคนิคในการเดิมพัน แต่บริการเหล่านี้ได้รับการออกแบบโดยมนุษย์จึงไม่สมบูรณ์
หากในที่สุดกลุ่มการปักหลักมีขนาดใหญ่เท่ากับพูลการขุด eth1 ก็เป็นไปได้ว่าจุดบกพร่องอาจทำให้เกิดการเฉือนจำนวนมากหรือบทลงโทษสำหรับการไม่มีการใช้งานสำหรับสมาชิก
🔗 อินฟูร่าล้มเหลว
เมื่อเดือนที่แล้ว Infura ลงไป 6 ชั่วโมง ทำให้เกิดการขัดข้องทั่วทั้งระบบนิเวศ Ethereum เป็นเรื่องง่ายที่จะดูว่าสิ่งนี้มีแนวโน้มที่จะส่งผลให้เกิดความล้มเหลวที่สัมพันธ์กันสำหรับผู้ตรวจสอบความถูกต้องของ eth2 อย่างไร
นอกจากนี้ ผู้ให้บริการ eth1 API บุคคลที่สามจำเป็นต้องเรียกใช้บริการแบบจำกัดอัตรา: ในอดีตสิ่งนี้ทำให้ผู้ตรวจสอบความถูกต้องไม่สามารถสร้างบล็อกที่ถูกต้องได้ (บน Medalla testnet)
ทางออกที่ดีที่สุดคือการรันโหนด eth1 ของคุณเอง: คุณจะไม่มีการจำกัดอัตรา แต่จะช่วยลดโอกาสที่ความล้มเหลวของคุณจะสัมพันธ์กัน และจะปรับปรุงการกระจายอำนาจของเครือข่ายโดยรวม
ไคลเอนต์ Eth2 ได้เริ่มเพิ่มความเป็นไปได้ในการระบุโหนด eth1 หลายอัน ซึ่งทำให้ง่ายต่อการสลับไปยังตำแหน่งข้อมูลสำรอง ในกรณีที่ตำแหน่งข้อมูลหลักของคุณล้มเหลว (Lighthouse: –eth1-จุดสิ้นสุดปริซึม: ประชาสัมพันธ์#8062Nimbus & Teku มีแนวโน้มที่จะเพิ่มการสนับสนุนที่ไหนสักแห่งในอนาคต)
ฉันขอแนะนำอย่างยิ่งให้เพิ่มตัวเลือก API สำรองเป็นการประกันราคาถูก/ฟรี (EthereumNodes.com แสดงจุดสิ้นสุด API แบบฟรีและแบบชำระเงินและสถานะปัจจุบัน) สิ่งนี้มีประโยชน์ไม่ว่าคุณจะใช้งานโหนด eth1 ของคุณเองหรือไม่ก็ตาม
🦏 ความล้มเหลวของไคลเอนต์ eth2 โดยเฉพาะ
แม้จะมีการตรวจสอบโค้ด การตรวจสอบ และการทำงานระดับสุดยอด แต่ไคลเอนต์ eth2 ทั้งหมดก็มีข้อบกพร่องซ่อนอยู่ที่ไหนสักแห่ง ส่วนใหญ่ยังเป็นผู้เยาว์และจะถูกตรวจจับได้ก่อนที่จะเกิดปัญหาสำคัญในการผลิต แต่ก็มีโอกาสเสมอที่ไคลเอนต์ที่คุณเลือกจะออฟไลน์หรือทำให้คุณถูกตัดทอน หากเกิดเหตุการณ์นี้ขึ้น คุณจะไม่ต้องการใช้งานไคลเอ็นต์ที่มีโหนดมากกว่า 1/3 บนเครือข่าย
คุณต้องประนีประนอมระหว่างสิ่งที่คุณคิดว่าเป็นลูกค้าที่ดีที่สุดกับความนิยมของลูกค้ารายนั้น ลองอ่านเอกสารประกอบของไคลเอ็นต์อื่นอย่างละเอียด เพื่อที่ว่าหากมีสิ่งใดเกิดขึ้นกับโหนดของคุณ คุณจะรู้ว่าจะเกิดอะไรขึ้นในแง่ของการติดตั้งและกำหนดค่าไคลเอ็นต์อื่น
หากคุณมี ETH จำนวนมาก อาจคุ้มค่าที่จะเรียกใช้ลูกค้าหลายรายโดยแต่ละรายมี ETH บางส่วนเพื่อหลีกเลี่ยงการใส่ไข่ทั้งหมดไว้ในตะกร้าใบเดียว มิฉะนั้น, รับรอง เป็นข้อเสนอที่น่าสนใจสำหรับโครงสร้างพื้นฐานการวางเดิมพันแบบหลายโหนดและ เครื่องมือตรวจสอบความลับที่ใช้ร่วมกัน จะเห็นการพัฒนาอย่างรวดเร็ว
🦢 หงส์ดำ
แน่นอนว่ามีสถานการณ์ที่ไม่น่าเป็นไปได้ คาดเดาไม่ได้ แต่เป็นอันตรายมากมายที่มักมีความเสี่ยงอยู่เสมอ สถานการณ์ที่อยู่นอกเหนือการตัดสินใจที่ชัดเจนเกี่ยวกับการตั้งค่าการเดิมพันของคุณ ตัวอย่าง เช่น อสุรกาย และ ล่มสลาย ในระดับฮาร์ดแวร์หรือข้อบกพร่องของเคอร์เนลเช่น เลือดออกฟัน บอกเป็นนัยถึงอันตรายบางอย่างที่มีอยู่ในสแต็กฮาร์ดแวร์ทั้งหมด ตามคำจำกัดความแล้ว ไม่สามารถคาดการณ์และหลีกเลี่ยงปัญหาเหล่านี้ได้ทั้งหมด แต่โดยทั่วไปแล้วคุณจะต้องตอบสนองตามความเป็นจริงแทน
สิ่งที่ต้องกังวล
ท้ายที่สุดแล้วสิ่งนี้ขึ้นอยู่กับการคำนวณค่าที่คาดหวัง อดีต) ของความล้มเหลวที่กำหนด: โอกาสที่เหตุการณ์จะเกิดขึ้น และสิ่งที่จะลงโทษหากเกิดเหตุการณ์ดังกล่าว การพิจารณาความล้มเหลวเหล่านี้เป็นสิ่งสำคัญในบริบทของเครือข่าย eth2 ที่เหลือ เนื่องจากความสัมพันธ์ส่งผลกระทบอย่างมากต่อบทลงโทษที่มีอยู่ การเปรียบเทียบต้นทุนที่คาดหวังจากความล้มเหลวกับต้นทุนในการบรรเทา จะทำให้คุณได้รับคำตอบอย่างมีเหตุผลว่าคุ้มที่จะแซงหน้าหรือไม่

ไม่มีใครรู้ทุกวิธีที่โหนดสามารถล้มเหลวได้ และความล้มเหลวแต่ละครั้งจะเป็นอย่างไร แต่ด้วยการประมาณการโอกาสของความล้มเหลวแต่ละประเภทเป็นรายบุคคล และลดความเสี่ยงที่ใหญ่ที่สุด “ภูมิปัญญาของฝูงชน” จะมีชัยเหนือและโดยเฉลี่ยของเครือข่าย โดยรวมจะประมาณการได้ดี นอกจากนี้ เนื่องจากความเสี่ยงที่แตกต่างกันซึ่งผู้ตรวจสอบแต่ละรายต้องเผชิญ และการประมาณการความเสี่ยงเหล่านั้นที่แตกต่างกัน ความล้มเหลวที่คุณไม่ได้คำนึงถึงจะถูกผู้อื่นจับได้ ดังนั้นระดับของความสัมพันธ์จะลดลง เย้ การกระจายอำนาจ!
📕 อย่าตกใจ
สุดท้ายนี้ หากมีอะไรเกิดขึ้นกับโหนดของคุณ อย่าเพิ่งตกใจ! แม้ในระหว่างที่ไม่มีการใช้งานการรั่วไหล บทลงโทษก็มีน้อยในช่วงเวลาสั้นๆ ใช้เวลาสักครู่เพื่อไตร่ตรองว่าเกิดอะไรขึ้นและทำไม แล้วจัดทำแผนปฏิบัติการเพื่อแก้ไขปัญหา จากนั้นหายใจเข้าลึกๆ ก่อนดำเนินการต่อ การลงโทษเพิ่มอีก 5 นาทีดีกว่าถูกเฉือนเพราะคุณทำสิ่งที่ไม่เหมาะสมในการเร่งรีบ
ที่สำคัญที่สุด: 🚨 อย่ารัน 2 โหนดด้วยคีย์ตัวตรวจสอบเดียวกัน!
ขอบคุณ Danny Ryan, Joseph Schweitzer และ Sacha Yves Saint-Leger สำหรับการตรวจสอบ
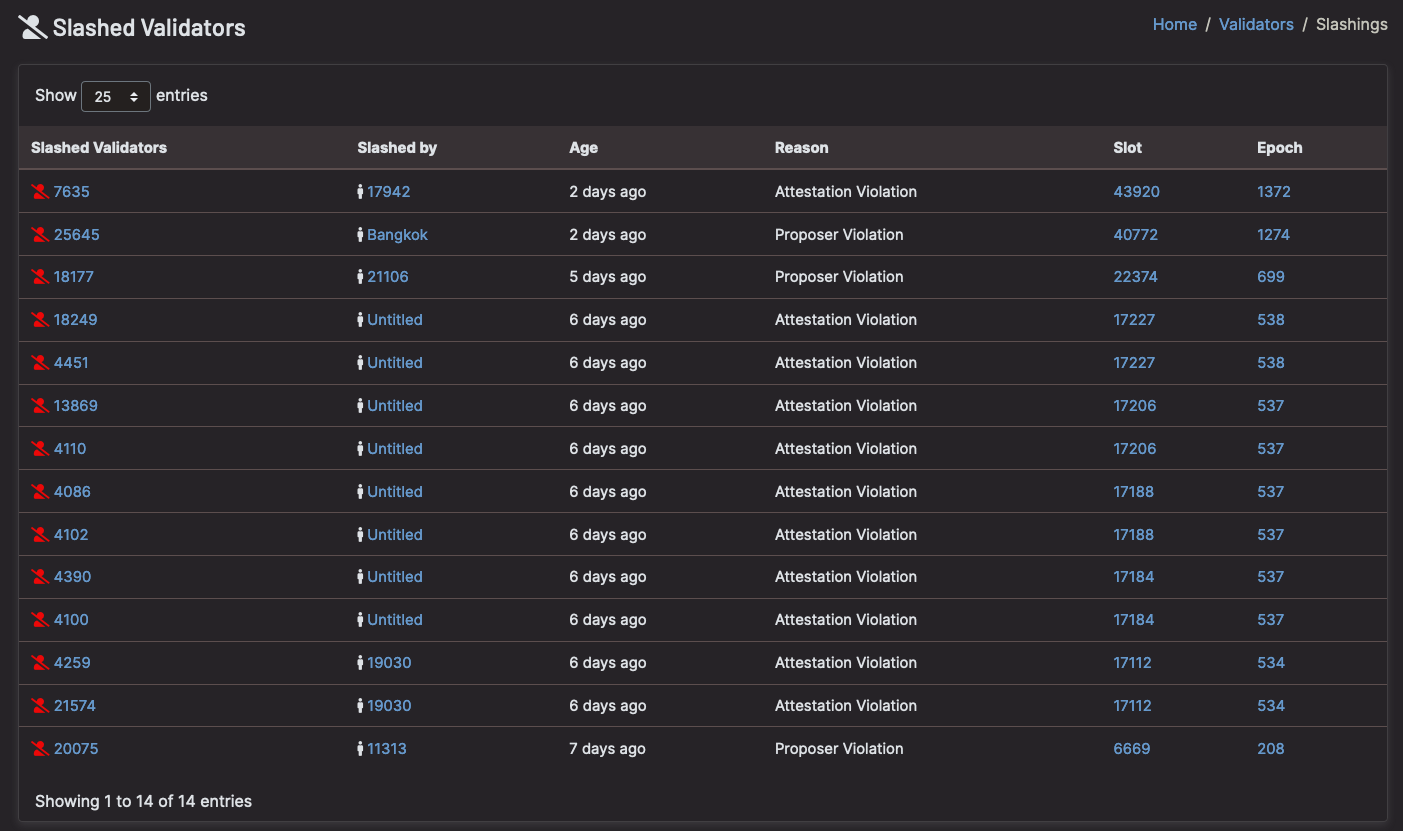
(เฉือนเพราะเครื่องมือตรวจสอบรัน >1 โหนด – บีคอนชา.อิน–